1) 사용자별 쿼리를 실행한 총 횟수를 구하는 쿼리를 작성해주세요. 단, GROUP BY를 사용해서 집계하는 것이 아닌 query_logs의 데이터의 우측에 새로운 컬럼을 만들어주세요.
--1번 의도 : COUNT를 윈도우 함수로 쓸 수 있는가?
--로그 : 통나무에서 왔음, 히스토리, 기록 --로그성 데이터 : 기록이 한 줄에 하나씩(Row). Raw. 이벤트 데이터 > 어떤 유저가 무엇을 했다 --고객에게(유저에게) 노출을 하지 않음 --회사마다 다름. AWS 라는 클라우드의 저장소 -> 데이터 웨어하우스, 데이터베이스 --Google Analytic 4, Firebase 플랫폼을 사용해서 데이터 저장하면 생기는 형태 --앱 로그, 웹 로그 --형태가 개발자가 어떻게 개발하냐에 따라서 그냥 못생긴 형태도 있음 --데이터 엔지니어가 Table 형태로 가공해서 줌 --데이터베이스 데이터 : 거래와 관련된 데이터. 배민. 주문 데이터. 주문 목록 --MySQL, PostgreSQL, Oracle
SELECT
*,
--사용자별! => user
COUNT(*)OVER(PARTITIONBYuser)AScnt
FROM`advanced.query_logs`
ORDERBYuser,query_date
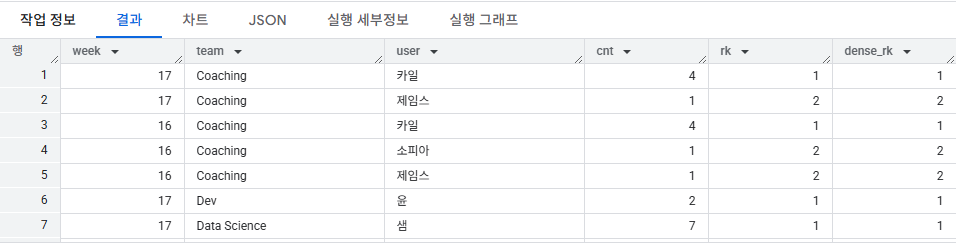
2) 주차별로 팀 내에 서 쿼리를 많이 실행한 수를 구한 후, 실행한 수를 활용해 랭킹을 구해주세요. 단, 랭킹이 1등인 사람만 결과가 보이도록 해주세요
--우리가 만들어야 하는 것 : WEEK | user | team | query_date | cnt
--최종적으로 만들어야 할 것 : WEEK | user | team | query_date | cnt | rk
--rk 가 1인 것만
--COUNT 그냥 집계랑, 윈도우 COUNT를 언제 해야할까? 기준이 있을까?
--데이터 형태에 맞게 적절하게 수행을 하는데, 최종적으로 보여줄 형태의 데이터에서
--하나의 Row 우측에 컬럼을 추가할 것인가? => 윈도우 함수
--한 번 집계를 하고 그 결과에 우측에 컬럼을 붙여야 하는가? => 그 전에는 집계 함수, 그 후에 윈도우 함수